すっきりSQL→達人に学ぶDB設計徹底指南書を読んだ。【設計・正規化の簡単な説明】
はじめに
前回に引き続きDBについてのミックが著書「達人に学ぶDB設計徹底指南書」を読んだ所感のうち【良かったところ/学んだこと・悪かったところ/難しかったこと】を書いていきます。
本書はこちらです。私は中古購入で紙媒体で読みましたが、電子版は偶にセール対象にもなるようでお得っぽいですね。 達人に学ぶDB設計 徹底指南書 初級者で終わりたくないあなたへ | ミック |本 | 通販 | Amazon
良かったところ
すっきりわかるSQLでも最後にDB設計は説明されるのですが、ちょっと話が急で単語への脈略がなさすぎて理解が難しい印象でした。
本書では、「なぜ→どのように→どうなるか」と順を追って丁寧に説明されていたり、比喩表現を用いていたりでとても理解がしやすいです。
また、要所で【勘どころ】と題して抑えるポイントを教えてくれます。それはもう「勘どころだけ押さえておけばいいのでは......?」と思ってしまうほどにです。
学んだこと
論理設計と物理設計の説明から、正規化の手法、ER図の読み方・作成方法、パフォーマンス設計、RDBMSで木構造を扱うためのSQLモデリング。と、学びましたが、特に論理設計とパフォーマンスの説明に力を入れていました。
全てを説明するのはとんでもないので設計と正規化について軽く説明します。
論理設計・物理設計
設計は論理設計(データの要素やデータ同士の関係)→物理設計(デーブルやインデックス等の物理的定義)という順で進行します。
何事も設計図を作ってから作り上げるのが基本です。
論理設計
論理設計は4ステップで行います。
【エンティティ抽出→エンティティ定義→正規化→ER図作成】です。
エンティティ抽出というのは、そのままですがどのようなエンティティ(データ)が必要かを洗い出すことです。ここは、顧客との要件定義や理詰めが必要不可欠です。 その後、各エンティティがどのような属性を保持するかを【エンティティ定義】で決定します。
物理設計
物理設計は5ステップで行います。【テーブル定義→インデックス定義→ハードウェアサイジング→ストレージの冗長構成定義→ファイルの物理配置定義】です。
インデックスというのは本の索引のようなもので、DBMSがクロールする手間を短縮できるためパフォーマンスが向上します。
ハードウェアサイジングというのは、「システムで利用するデータサイズを見積り、それに合わせたストレージを選定する」作業です。大は小を兼ねるですが、あまりにも大きすぎるとコストがかかりますし、少なすぎるとサービスの運営が終わります。昨今はAWSやGCPなどがあるのでいいですね。
ストレージの冗長構成定義とは難しそうに聞こえますが、どれだけデータの耐久性を持たせるかの定義です。RAIDという技術があるのですが、これは複数のストレージを用いてデータを分散させることにより可逆性を持たせよう!みたいな技術です。
ここも、どのようなデータ配置にするか(耐久性管理)と、ストレージをどれだけ使うか(コスト管理)のシステムに合わせたいい塩梅を見つけなければなりません。
正規化
本書のメインコンテンツともいっていいほどだった正規化。 正規化というのはDBに保持するデータの冗長性を排除し、保守管理をしやすくする手法です。
正規化を勉強して感じたのは、「異なるエンティティレベルを探し出す洞察力」が上手い人が上手く正規化できるな。という点でした。
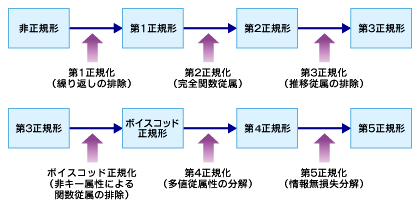
正規化も保守管理性とパフォーマンス性が反比例なのでいい塩梅を見つけないとですが、たいていの場合は、第三正規形までできていれば運用に事足りるとのことでした。
前提
正規化の前提は可逆性があるかどうかです。簡単にいえばバラバラにしたテーブルを後から再結合した際、元の状態に戻せるかどうか。ということです。
第一正規形
定義は【一つのセルの中には一つの値しか含まない】です。
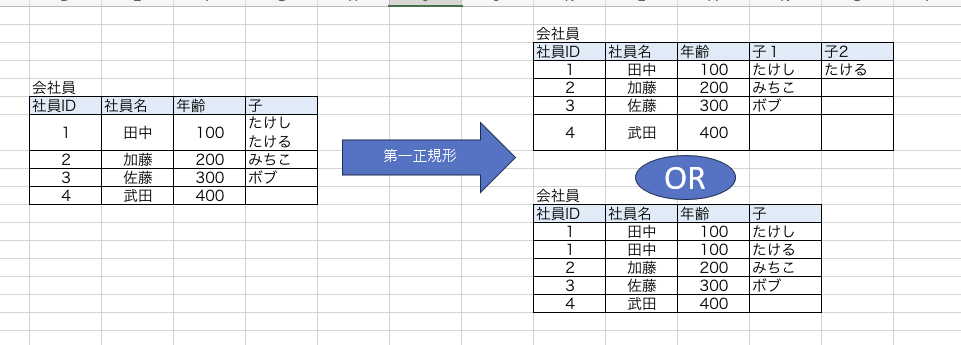
一つのセルに一つの値が含まれている状態をスカラ値といいます。
ただしこのままだと、問題があります。
例えばすべての社員が子を持っているわけではない。ということなど。
子がないセルにはNULLが主に代入されることが多いですが、プライマリキー(以下:PK)が厳密に定義されていないこのテーブルは全てがPKの候補となってしまい、
NULLを代入するとPK定義のルール違反です。(PKは一部であってもNULLが代入されているのは許されない)。
なのでテーブル分割を行います。
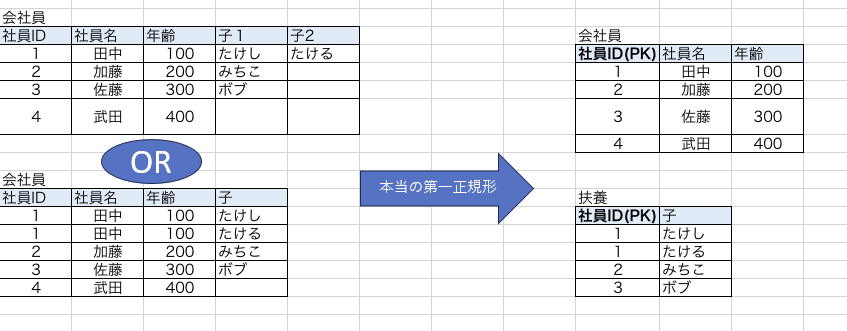
こんな感じです(多分)。可逆性も保持しています。
第二正規形
定義は【部分関数従属を排除し、PKに対して完全関数従属にする】です。
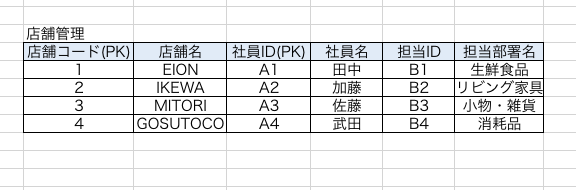
このテーブルのPKは【店舗コードと社員ID】です。
この2つのPKに他の非キーが全て従属しなければならないのですが、見てみると【店舗名】がPKの一部である店舗コードに従属しており、社員IDには従属していません。
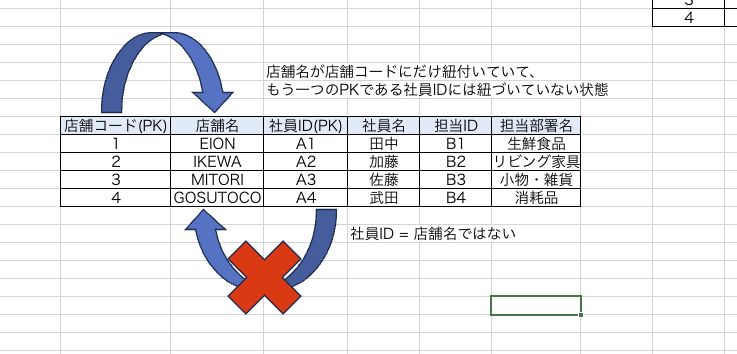
このようにPKの一部に対して従属する列を部分関数従属といいます。
もう一度いいますが、第二正規形の定義は【部分関数従属を排除し、PKに対して完全関数従属にする】です。
なので、少々強引ですがこの部分関数従属している部分だけ分割してしまいましょう。そうすればすべてのPKに従属する完全関数従属になると思いませんか?

強引ですが、定義上はOKでしょう(多分)。可逆性も保持しています。
なぜ、第二正規形が必要なのか少し考えてみましょう。
・・・・・・。
......もう第二正規化する前のテーブルを見てみましょう。
例えば、新たな店舗【FAMILYBARD】を運営することと決定し、このテーブルに追加することにしましょう。ただし、店舗はまだ建設途中なので具体的な社員は居ないこととします。
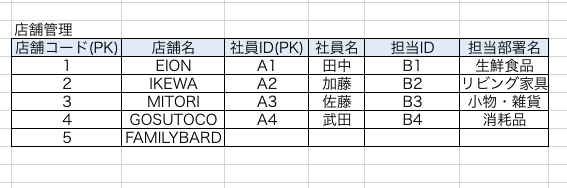
このテーブルの状態だと、社員が居ないため該当するセルにはNULLが代入されることになるでしょう。
ですが、NULLを代入するとPK定義のルール違反です。(PKは一部であってもNULLが代入されているのは許されない)。
つまり、正規前のテーブルでは【新店舗が決まり、社員決まらないとテーブルに追加できない状態】であるといえます。なんと不便でしょうか・・・。
ですが、第二正規化後は店舗情報をテーブル分割して保持しているため、【社員が決まってなくても店舗情報を追加できる状態】です。
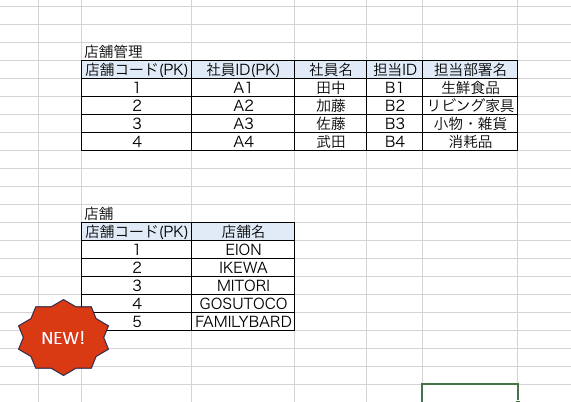
これなら問題さそうです。
第二正規形にすることで【新店舗が誕生しても、テーブルに情報を追加できる柔軟性】を持たせることができました。
第三正規形
定義は【推移的関数従属を排除する】です。
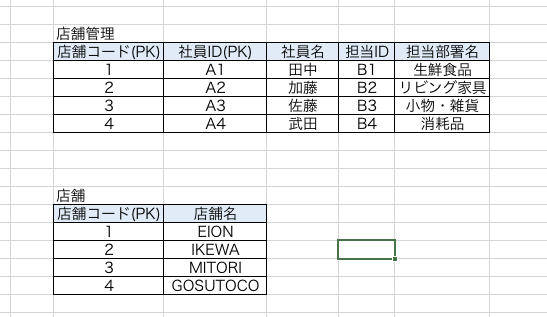
今度は【担当IDと担当部署】に着目します。
例えばですが、各店舗には【販売担当】という担当部署が存在していたとします。店舗なので販売員がいるのは必然ですよね。
ただ、このテーブルの人たちは【販売担当という部署には分類されていないだけ】だとしたら?このテーブルの状態だと、販売担当という部署が存在することなど到底判別がつきません。
こういう担当社員が居ない部署を先ほどの第二正規化後のテーブルには追加することはできません。理由は、第二正規形の節でも述べた通り、NULLが代入されるとPK定義違反です。
このようなケースになる理由は、第二正規化後の中にもまだ別の関数従属が残っているためです。

この関数従属の中に関数従属がネストされている状態を推移的関数従属といいます。
第三正規形の定義はこの推移的関数従属を排除することです。つまりやることはテーブル分割です。
そう、正規化っていうのは言ってしまえばテーブル分割を行いどれだけテーブルを単一責任にするか、なんですねぇ〜。
ということで、分割したものがこちらです。
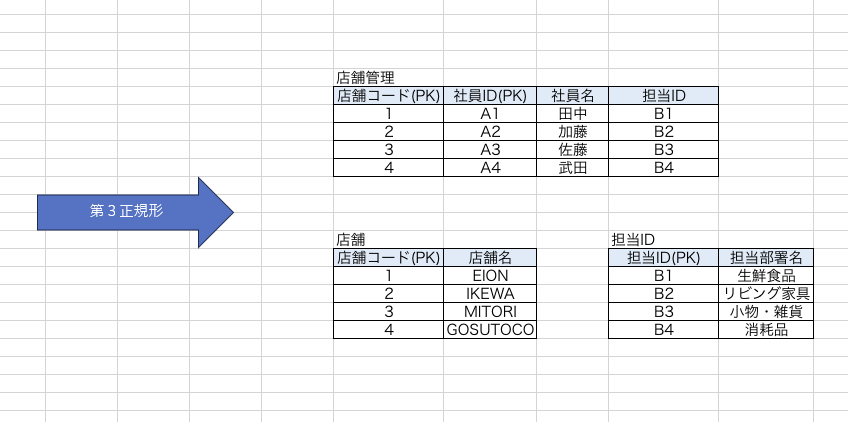
やっていることは第二正規化と一緒です。PKを用意し分割するだけですね。
これで【販売担当】という担当部署を追加することができますね。
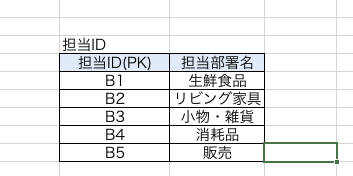
もちろん可逆性も保持しています。
正規化のトレードオフ
一般的に正規化を行うことでこのような利点があります。
- データの冗長性が排除され、更新時の不具合を防止できる。
- テーブルの持つ意味が明確となり、理解しやすい。
しかし、当然ながらデメリットも存在します。
- テーブルの数が増えるため、必然的にパフォーマンス性が悪いSQL文の結合を多用することになる。つまり、処理が遅くなる。
基本的に正規レベルが上になるにつれ、テーブル数が増えるためパフォーマンス性が悪くなります。
正規化とはデータの整合性とパフォーマンス性のトレードオフの関係性があり、いい塩梅を見つけなければなりません。
例えば金融機関のDB設計では、顧客情報管理がなりよりなので、パフォーマンス重視よりも高次元正規化にするべきです。(某カードみたいに不整合があったら炎上案件です。)
つまり、何を目的で何が大事かを確認し、それに合わせた設計にするべきなんですね。ケースバイケースです。
おわりに
本書ではパフォーマンスと保守性のトレードオフについてたびたび触れていました。例えばインデックスも作りすぎるとデータ裁量的にパフォーマンスが落ちますし、かといって作らないとパフォーマンスを向上させることができません。これもトレードオフです。
いい塩梅を見つけ、上手く設計するには顧客とのすり合わせが大事です。DB設計とは顧客とエンジニアの互いの認識をどれだけ明確にし、合わせるかに尽きるのかもしれませんね。