Happiness Chainに入会して大体半年経ったので所感を綴る
Happiness Chainに入会して大体半年経ったので所感を綴る
前回の記事はこちら →

こんにちは、Riku Pikuです。本日は6/28でいつのまにか入会してから大体半年ほど経ちます。
いやーーーーーっっ、早いっっっっっっ!!!!
前回記述したのが3月の終わりですので、4月から換算して大体二ヶ月間で何をしてきたか、とりあえず書きます。
学んだこと
section的にはRuby節修了、現在DB周りの節を進めています。
カリキュラム内容に関しては、ゆうだいさん twitter.com
やHC公式HPで発信されています。
Rubyで大苦戦したお話
Rubyの節で大苦戦し一ヶ月くらい溶かしました。何が難しかったかというとオブジェクト指向プログラミングを用いた課題でした。
(たった一つの課題で26conversation,6 commitと沼)
Rubyの書き方自体は教材でインプットしてすぐ理解できました。ですが、オブジェクト指向という概念が抽象的で混乱してしまいました。
「そもそもどこでクラスを分けるべきなの?」「どれくらいの責任を持たせるべきなの?」と......。
メンターさんから「結構迷える子羊さんになっちゃってますねw」と言われるほどでした;;;
ここで、インプットが足りないんだな。と思い、追加教材を二冊ほどこなしました。
楽しいRuby第6版
たのしいRuby 第6版 (Informatics&IDEA) | 高橋 征義, 後藤 裕蔵 |本 | 通販 | Amazon
と、オブジェクト指向設計実践ガイド ~Rubyでわかる 進化しつづける柔軟なアプリケーションの育て方です
オブジェクト指向設計実践ガイド ~Rubyでわかる 進化しつづける柔軟なアプリケーションの育て方 | Sandi Metz, 髙山 泰基 |本 | 通販 | Amazon
楽しいRubyに関してはRubyの生みの親であるMatzさんが監修のこともあり、めちゃくちゃに詳しく書かれていました。(途中意味がわからないところもあるほどに)
オブジェクト指向設計ガイドは、訳書特有の読みにくさと内容の難しさで頭吹き飛びそうになりましたが、だいぶ理解が進みました。この本を読まなかったらもっと課題に時間をかけていたでしょう。
なかなかPRが通らず気絶しかけましたが無事マージすることができて安心しました。いやー、「僕、ここで脱落すんの?!」とも思いましたがなんとか。
反省点
Rubyの課題を作成する際、前章で学んだDockerで環境構築を行えば良かったなーっと終了後に感じました。恐ろしいことに人間というのは一ヶ月間使わないことは大体忘れているのだから.....。( Dockerはモダンな会社では必須技術ですのでぱぱーっと環境構築できるように普段から使うべきだな、と。いくら課題で「Dockerで環境構築を行なってください」と指定されていないからといって怠けるのは未来の僕の足枷でした。
DBも若干萎えた
DB sectionのSQLインプット節でも若干萎えました。あるSQLドリルを用いてインプットを行うのですが、これがほんっっっっっとに難しくて.......。そもそも、問題文を解読できないんですね。なので当然答えはほぼ間違っている。再度インプットを行なってもドリルが意味わからなすぎて「え、僕言語障害でもあるんすか.....?」となりました。
HCのSlackで病み垢ツイートみたいなことをしたら同じような方がいて救われたのはいい思い出(?)です。
まぁ、例の如くインプット不足だと思って追加教材をこなしました。 ゼロからはじめるデータ分析のための実践的SQL入門〜最短経路で現場で使えるSQLを習得〜 という Udemyの教材です。
https://www.udemy.com/course/sql_for_data_analytics/
これは超!わかりやすい神教材でした。講師がex.株式会社リブセンスやメルカリなので信頼性もありました。これを受講して思いました。ただドリルが難しすぎただけだと・・・。
SQL文がかけるようになったらあとはDBの設計ですね。
こちらもインプット教材が指定されているのですが、めちゃくちゃわかりやすくてストレスフリーでした。これが幸せってやつか。
現在、DB設計に関しての課題であるブログを提出して確認をもらっている最中です。これが通れば次は「では実際にDB設計してみようね!はいこれ!」と結構難しそうな課題出されてますので頑張るだけですね。
コミュニティでの動きを活発にした
あと、この数ヶ月間で変えたことといえばコミュニティでの動きを若干活発にしたことです。Slackのtimesで質問を投げている方にコメントをしたり、オヌヌメツールを紹介したりで若干コミュニティに貢献してます感を出すようにしました。
たまに間違ったことをいいますが、そこはつよつよメンターさんが訂正してくださりますのでお互いWin-Winですので良しです。
あとは、Twitterのアカウントを分けました。理由はこれです。
Twitterを適当に使っていませんか?
— ゆうだい|プログラミングをゼロから教えるプロ (@yudai_on_rails) June 15, 2023
Web系エンジニアの転職活動は職務経歴書にブログ・Qiita・Twitter・GitHubのアカウントを乗せます。Twitterは人柄がよく出ます。就職に使うアカウントなら変なことを呟かないように気をつけましょう。
私が採用担当をするときは人のいいね欄まで詳しくみますw…
対して僕のツイートがこれ
わかるさんのダミxア成長Ifが尊いっっっっっっっっっっ!!!!!!!!!!(朝からすみません)
— Riku Piku (@RikuPiku_) June 10, 2023
まずいですね!!!!
ということで新しいアカウントを作ったのでよろしくお願いします。
根っこがヲタクだからしょうがないね。
おわりに
カリキュラム的に進行スピードは亀さんですが、しっかりと手応えを感じています。 正直さっさとRailsを学びたいのですが、焦らずやっていきたい所存です。
ブログはうまい感じに続けていきたいですね。今回の執筆も書くまでにまさに重い腰を上げるに等しかったので。(ろくな内容書かないくせに....)
ではまた二ヶ月後に・・・・。
すっきりSQL→達人に学ぶDB設計徹底指南書を読んだ。【設計・正規化の簡単な説明】
はじめに
前回に引き続きDBについてのミックが著書「達人に学ぶDB設計徹底指南書」を読んだ所感のうち【良かったところ/学んだこと・悪かったところ/難しかったこと】を書いていきます。
本書はこちらです。私は中古購入で紙媒体で読みましたが、電子版は偶にセール対象にもなるようでお得っぽいですね。 達人に学ぶDB設計 徹底指南書 初級者で終わりたくないあなたへ | ミック |本 | 通販 | Amazon
良かったところ
すっきりわかるSQLでも最後にDB設計は説明されるのですが、ちょっと話が急で単語への脈略がなさすぎて理解が難しい印象でした。
本書では、「なぜ→どのように→どうなるか」と順を追って丁寧に説明されていたり、比喩表現を用いていたりでとても理解がしやすいです。
また、要所で【勘どころ】と題して抑えるポイントを教えてくれます。それはもう「勘どころだけ押さえておけばいいのでは......?」と思ってしまうほどにです。
学んだこと
論理設計と物理設計の説明から、正規化の手法、ER図の読み方・作成方法、パフォーマンス設計、RDBMSで木構造を扱うためのSQLモデリング。と、学びましたが、特に論理設計とパフォーマンスの説明に力を入れていました。
全てを説明するのはとんでもないので設計と正規化について軽く説明します。
論理設計・物理設計
設計は論理設計(データの要素やデータ同士の関係)→物理設計(デーブルやインデックス等の物理的定義)という順で進行します。
何事も設計図を作ってから作り上げるのが基本です。
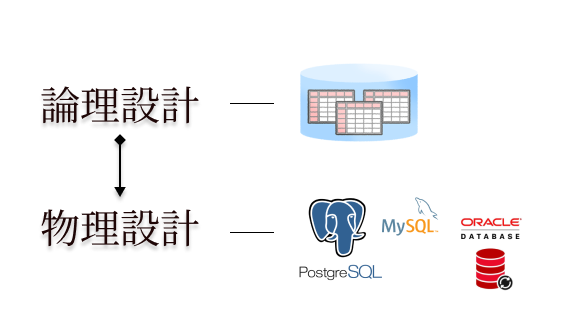
論理設計
論理設計は4ステップで行います。
【エンティティ抽出→エンティティ定義→正規化→ER図作成】です。
エンティティ抽出というのは、そのままですがどのようなエンティティ(データ)が必要かを洗い出すことです。ここは、顧客との要件定義や理詰めが必要不可欠です。 その後、各エンティティがどのような属性を保持するかを【エンティティ定義】で決定します。
物理設計
物理設計は5ステップで行います。【テーブル定義→インデックス定義→ハードウェアサイジング→ストレージの冗長構成定義→ファイルの物理配置定義】です。
インデックスというのは本の索引のようなもので、DBMSがクロールする手間を短縮できるためパフォーマンスが向上します。
ハードウェアサイジングというのは、「システムで利用するデータサイズを見積り、それに合わせたストレージを選定する」作業です。大は小を兼ねるですが、あまりにも大きすぎるとコストがかかりますし、少なすぎるとサービスの運営が終わります。昨今はAWSやGCPなどがあるのでいいですね。
ストレージの冗長構成定義とは難しそうに聞こえますが、どれだけデータの耐久性を持たせるかの定義です。RAIDという技術があるのですが、これは複数のストレージを用いてデータを分散させることにより可逆性を持たせよう!みたいな技術です。
ここも、どのようなデータ配置にするか(耐久性管理)と、ストレージをどれだけ使うか(コスト管理)のシステムに合わせたいい塩梅を見つけなければなりません。
正規化
本書のメインコンテンツともいっていいほどだった正規化。 正規化というのはDBに保持するデータの冗長性を排除し、保守管理をしやすくする手法です。
正規化を勉強して感じたのは、「異なるエンティティレベルを探し出す洞察力」が上手い人が上手く正規化できるな。という点でした。
正規化も保守管理性とパフォーマンス性が反比例なのでいい塩梅を見つけないとですが、たいていの場合は、第三正規形までできていれば運用に事足りるとのことでした。
前提
正規化の前提は可逆性があるかどうかです。簡単にいえばバラバラにしたテーブルを後から再結合した際、元の状態に戻せるかどうか。ということです。
第一正規形
定義は【一つのセルの中には一つの値しか含まない】です。
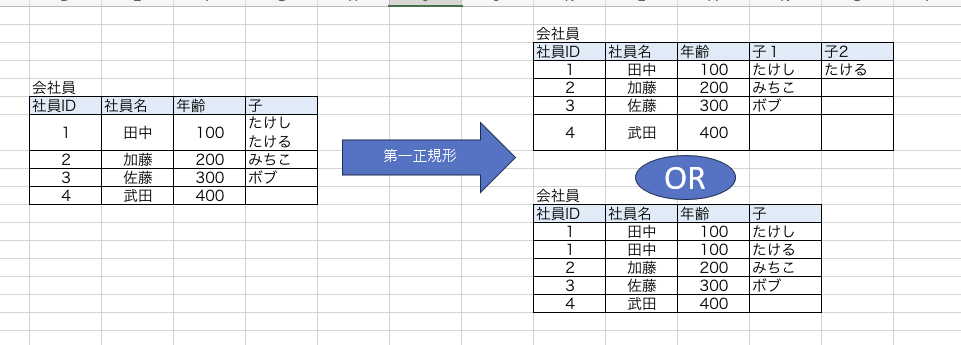
一つのセルに一つの値が含まれている状態をスカラ値といいます。
ただしこのままだと、問題があります。
例えばすべての社員が子を持っているわけではない。ということなど。
子がないセルにはNULLが主に代入されることが多いですが、プライマリキー(以下:PK)が厳密に定義されていないこのテーブルは全てがPKの候補となってしまい、
NULLを代入するとPK定義のルール違反です。(PKは一部であってもNULLが代入されているのは許されない)。
なのでテーブル分割を行います。
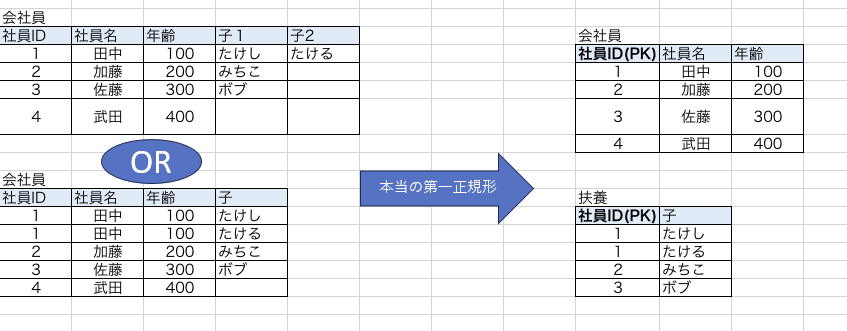
こんな感じです(多分)。可逆性も保持しています。
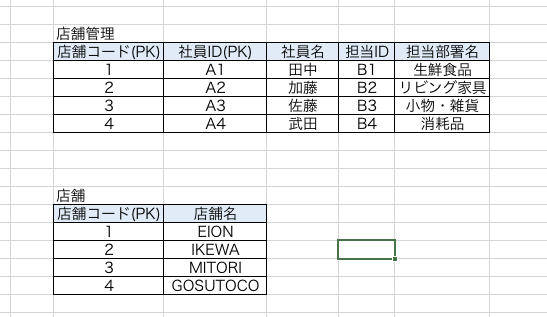
第二正規形
定義は【部分関数従属を排除し、PKに対して完全関数従属にする】です。
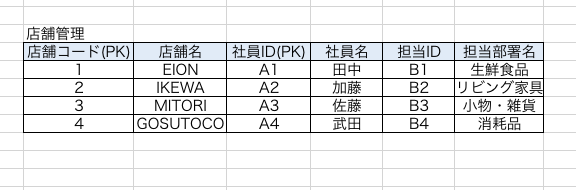
このテーブルのPKは【店舗コードと社員ID】です。
この2つのPKに他の非キーが全て従属しなければならないのですが、見てみると【店舗名】がPKの一部である店舗コードに従属しており、社員IDには従属していません。
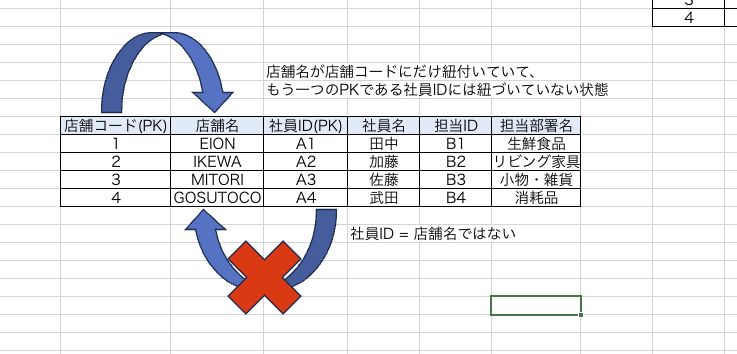
このようにPKの一部に対して従属する列を部分関数従属といいます。
もう一度いいますが、第二正規形の定義は【部分関数従属を排除し、PKに対して完全関数従属にする】です。
なので、少々強引ですがこの部分関数従属している部分だけ分割してしまいましょう。そうすればすべてのPKに従属する完全関数従属になると思いませんか?

強引ですが、定義上はOKでしょう(多分)。可逆性も保持しています。
なぜ、第二正規形が必要なのか少し考えてみましょう。
・・・・・・。
......もう第二正規化する前のテーブルを見てみましょう。
例えば、新たな店舗【FAMILYBARD】を運営することと決定し、このテーブルに追加することにしましょう。ただし、店舗はまだ建設途中なので具体的な社員は居ないこととします。
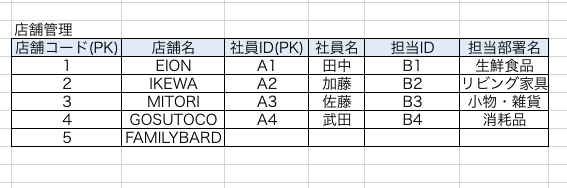
このテーブルの状態だと、社員が居ないため該当するセルにはNULLが代入されることになるでしょう。
ですが、NULLを代入するとPK定義のルール違反です。(PKは一部であってもNULLが代入されているのは許されない)。
つまり、正規前のテーブルでは【新店舗が決まり、社員決まらないとテーブルに追加できない状態】であるといえます。なんと不便でしょうか・・・。
ですが、第二正規化後は店舗情報をテーブル分割して保持しているため、【社員が決まってなくても店舗情報を追加できる状態】です。
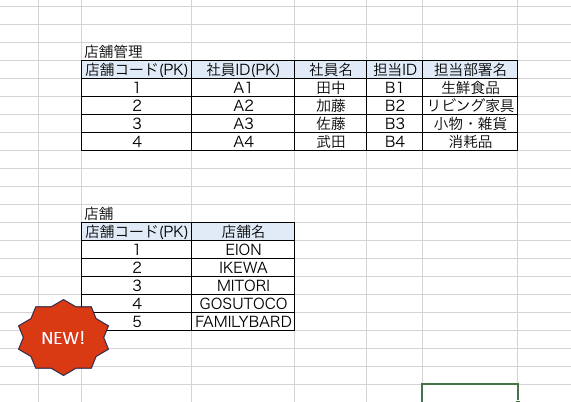
これなら問題さそうです。
第二正規形にすることで【新店舗が誕生しても、テーブルに情報を追加できる柔軟性】を持たせることができました。
第三正規形
定義は【推移的関数従属を排除する】です。
今度は【担当IDと担当部署】に着目します。
例えばですが、各店舗には【販売担当】という担当部署が存在していたとします。店舗なので販売員がいるのは必然ですよね。
ただ、このテーブルの人たちは【販売担当という部署には分類されていないだけ】だとしたら?このテーブルの状態だと、販売担当という部署が存在することなど到底判別がつきません。
こういう担当社員が居ない部署を先ほどの第二正規化後のテーブルには追加することはできません。理由は、第二正規形の節でも述べた通り、NULLが代入されるとPK定義違反です。
このようなケースになる理由は、第二正規化後の中にもまだ別の関数従属が残っているためです。

この関数従属の中に関数従属がネストされている状態を推移的関数従属といいます。
第三正規形の定義はこの推移的関数従属を排除することです。つまりやることはテーブル分割です。
そう、正規化っていうのは言ってしまえばテーブル分割を行いどれだけテーブルを単一責任にするか、なんですねぇ〜。
ということで、分割したものがこちらです。
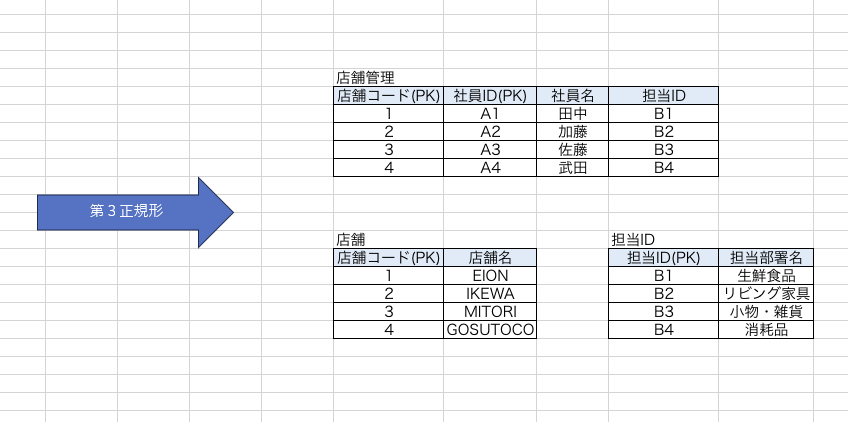
やっていることは第二正規化と一緒です。PKを用意し分割するだけですね。
これで【販売担当】という担当部署を追加することができますね。
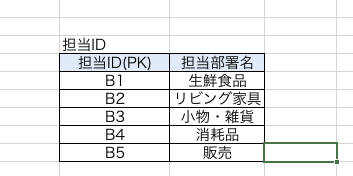
もちろん可逆性も保持しています。
正規化のトレードオフ
一般的に正規化を行うことでこのような利点があります。
- データの冗長性が排除され、更新時の不具合を防止できる。
- テーブルの持つ意味が明確となり、理解しやすい。
しかし、当然ながらデメリットも存在します。
- テーブルの数が増えるため、必然的にパフォーマンス性が悪いSQL文の結合を多用することになる。つまり、処理が遅くなる。
基本的に正規レベルが上になるにつれ、テーブル数が増えるためパフォーマンス性が悪くなります。
正規化とはデータの整合性とパフォーマンス性のトレードオフの関係性があり、いい塩梅を見つけなければなりません。
例えば金融機関のDB設計では、顧客情報管理がなりよりなので、パフォーマンス重視よりも高次元正規化にするべきです。(某カードみたいに不整合があったら炎上案件です。)
つまり、何を目的で何が大事かを確認し、それに合わせた設計にするべきなんですね。ケースバイケースです。
おわりに
本書ではパフォーマンスと保守性のトレードオフについてたびたび触れていました。例えばインデックスも作りすぎるとデータ裁量的にパフォーマンスが落ちますし、かといって作らないとパフォーマンスを向上させることができません。これもトレードオフです。
いい塩梅を見つけ、上手く設計するには顧客とのすり合わせが大事です。DB設計とは顧客とエンジニアの互いの認識をどれだけ明確にし、合わせるかに尽きるのかもしれませんね。
DBなんも分からん人がスッキリわかるSQL入門を読んだ
DBなんも分からん人がスッキリわかるSQL入門を読んだ
久しぶりの投稿です。現在、DB学習のフェーズに入り、すっきりわかるSQL入門という本を読んだ所感のうち【良かったところ/学んだこと・悪かったところ/難しかったこと】を書いていきます。
本書→https://amzn.asia/d/0ZFRG3n
前提
タイトルの通りですが、私はSQLやDB周り(以下:DB)はProgateで軽く触った程度で全くの無知識でした。
良かったところ
本書の特徴といえばなんと言っても「DokoQL」と「イラスト付きの会話形式での進行」でしょう。 DokoQLとはブラウザ上でSQL文の作成と実行ができる株式会社フレアリンク提供のクラウドサービスです。 各sectionのSQL文が事前にライブラリとして登録してあり、すぐ確認・実行ができるのが特徴です。
DBの環境構築は初心者には難解で、SQLの勉強開始前から詰んだとしたら元も子もないので、いい選択だと思いました。
また、第一部【SQLを始めよう】でDBやSQLとは?から始まり、最終第四部【データベースで実現しよう】でテーブルの設計まで計423Pと幅広く学ぶのですが、 前述した「イラスト付きの会話形式」の進行方向をとっているため、飽きずに読み進めることができました。
学んだこと
SQLのDMLからWHERE句の絞り込み、検索結果の加工(ORDER BY等)の基本的なSQL文。 サブクエリや複数テーブルの結合からトランザクション、テーブルの制約・高速化、テーブルの概念設計・論理設計・物理設計など少し深掘りしたところまで学ぶことが出来ました。
DML
DMLとはData Manipulation Languageの略称でSELECT/UPDATE/DELETE/INSERTの4大命令のことをいいます。
SQLはこのDMLが基本の命令体系で、これだけでほとんどの処理ができますがスコープが広すぎます。ここにWHERE句やORDER BY句などで修飾し、データを絞り出します。
たとえばこのようなmy_tableというテーブルがあるとします
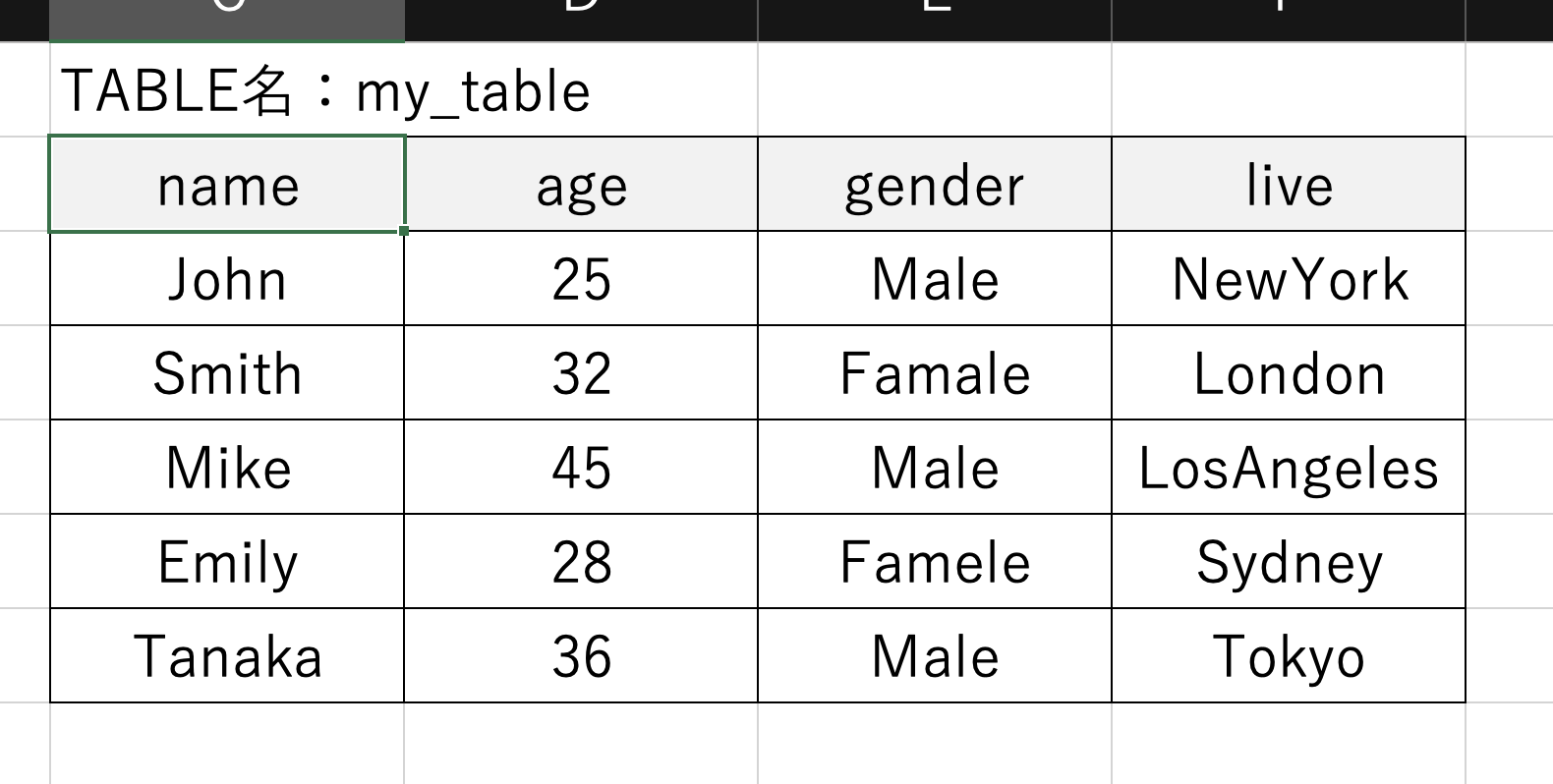
nameカラムを取り出すにはSELECTを用いてこのように記述します。
SELECT name FROM my_table
構文はSELECT カラム名 FROM テーブル名です。
WHERE句
先ほどのDMLではスコープが広すぎて、指定したカラムを全て取ってきてしまいます。
ここからさらに絞りこみをしたい場合はWHERE句を用います。
例えば名前がMikeのageを取得したい場合は、
SELECT age FROM my_table WHERE name = "Mike"
と記述します。
構文はWHERE 条件式です。
検索結果の加工
例えばですが、nameカラムとageカラムを取得かつ年齢順に並び替えたいというケースもあると思います。 SQLでは取り出したデータを並び替えたり"加工”することができます。
SELECT name,age FROM my_table ORDER BY age ASC
ORDER BY句を用いることで指定した列の値を基準として並び替えることが出来ます。
構文はORDER BY 列名 並び順です。
並び順はASC(昇順)とDESC(降順)です。
その他にも行数を制限するOFFSET - FETCH (LIMIT)や集合演算子のUNION,EXCEPT,INTERSECTなどがあります。
サブクエリ(複問い合わせ)
サブクエリとはSELECT文の中にSELECT文を書くことを指します。
例えばageが一番高い人のnameとageを取得したい場合は
SELECT name,age FROM my_table WHERE age = (SELECT MAX(age) FROM my_table)
と記述します。どうなっているかというと、最初に( )の中のSELECT文が先に処理され、結果がリターンされます。(今回は45)
つまりサブクエリが処理された時点でのWHERE句は以下のコードと同等です。
WHERE age = 45
もちろんサブクエリのSELECT文の中でWHEREでさらに絞り込むことも可能です。クエリはより内側にあるものから外側に向かって評価されていくと覚えておくと良いでしょう。
トランザクション
トランザクションとは、一つ以上のSQL文をひとかたまりとして扱うようにする処理方法です。かたまりにすることで例えば処理中に急にコンピュータがシャットダウンしてしまい、一連の処理が中途半端に中断され、その横から書き換えてしまう。といったケースを防いでくれます。
トランザクションを用いるには開始指示,終了指示(COMMIT/ROLLBACK)で処理を囲みます。
BEGIN; -- 処理1 -- なんらかの処理 -- 処理2 -- なんらかの処理 COMMIT;
COMMITはここまでの処理を確定させる終了指示。ROLLBACKはここまでの処理を取り消しさせる終了指示です。
これにより、トランザクションに含まれるSQL文は全て実行された or 一つも実行されていないの二択に保証されます。
制約
もちろんSQLは抽出だけではなくテーブルの生成もできます。
制約とはテーブルを作成する際、カラムにそぐわない値を代入させないようにすることです。例えばnameカラムに12という整数が代入されるのはおかしいですよね。
CREATE TABLE your_table ( name STRING NOTNULL, live STRIBG DEFAULT "不明" NOTNULL )
以上のコードはname,liveというカラムを持つyour_tableを作成します。作成する際にNOTNULL制約を用いて、「NULLの代入を許可しない」という"制約”をかけています。
liveカラムは何も代入されなかった(null)場合に、NOTNULL制約で判別をし、"不明"というデフォルトの値を代入するようにしています。
他にもUNIQUE制約 CHECK制約 PRIMARY KEY制約など様々な制約が存在します。
悪かったところ/難しかったところ
個人的にいくつかありました。
そもそもdokoQLが使いにくく不便でした。Google CloudのBigQueryでも良かったと思いました。
カラム名が日本語だったのが残念でした。おそらく現場では英表記ではないでしょうか、英to日や日to英の変換が頻繁に発生するので面倒に感じられました。
様々なRDBMSを取り上げすぎていて全てにおいて冗長でした。読者はSQLの書き方動かし方を理解したく、全てのRDBMSを理解したいわけではないので、個人的にはPostgreSQLとMySQLの2つだけでもいいとおもったのですが・・・。
インプットの難易度に対して、アウトプットの難易度が釣り合ってませんでした。本書は読むだけなら初心者でも簡単。ドリルを解こうとすると途端に難易度が豹変します。 理由としては、そもそも問題文が難解、問題用のテーブルがdokoQLに存在しないためトライアンドエラーがしようにも出来ないなどがあります。しっかりとSQL文の記法を理解してドリルに望んでみたらボコボコにされて、僕は言語障害があるのか?と若干ネガりました・・・それくらい難しかったです。
このように若干自信喪失をしたので、現在追加でUdemyで別の教材を買って進めているのですが、超絶楽ですので、やはりドリルの難易度は高いでしょう。 Udemy→https://www.udemy.com/course/sql_for_data_analytics/
- 最終章辺りのトランザクション〜テーブル設計が難しいです。こればっかりは個人の実力でしかないのでもっと勉強していきたいです。
おわりに
総評としては良かったです。なぜならば、SQLナンモワカランの人が最後ぐちぐち言えるぐらいまでの知識量は付いたことを証明しているためです。
初めて別の言語を学習した所感
僕はいままでJavascript(以下:js)しか触ってこなかったのですが、HCの課題でRubyを学習したので所感を綴ります! 特に前記事の続きとかでもないので、興味ある方だけ見ていってください。 前記事はこちら→
使用した教材
用いた教材はプロを目指す人のためのRuby入門[改訂2版] (通称:チェリー本)です。 https://amzn.asia/d/35n01yu
Rubyの言語仕様からテスト駆動開発・デバッグ技法まで幅広く学習することができます。
感想
さっそく感想です。簡単に言えばjsを事前に触っていたおかげで学習をスムーズに進め、おおまかに理解することができたに尽きます。
これでは記事が短すぎるので少し深掘りします。
Ruby特有の記述が気持ち悪かったが、学習後だと有り難みが分かる。
Rubyには"ブロック"という概念があり、これはjsには存在しませんでした。
ブロックというのはメソッドの引数として渡すことのできる処理の塊のようなものですが、これの記述方法がなんか...気持ち悪かったんですよね〜。
例えばjsのループ処理
const array = [1, 2, 3 ,4 ,5];
let sum = 0;
for(let i = 0; i < array.length; i++){
sum += array[i]
};
console.log(sum)
// sum = 15
対してRubyのループ処理
array = [1, 2, 3, 4, 5] sum = 0 array.each do | n | sum += n end puts sum # sum = 15
初めは|(パイプ)とかdo / endとか変数/定数の宣言がなかったりただ違和感だらけでしたが、
いや〜改めて見るとrubyの方が分かりやすいですね・・・!
学習中はそうでもなかったのですが、学習後にコードを見てみると明らかにjsより可読性が高いと思いました。
rubyの処理方法はdo 後の| "n" | にarrayをひとずつ つっこんでいって、
sum に加算してます。jsのmapメソッドとかも似たような挙動ですね!
%記法とかいう滅茶苦茶便利やヤツが居る
%記法を使えば配列をパパッとつくれちゃいます。
array = %w!10 20 30 40! puts array # 10 # 20 # 30 # 40
クリーンコードを意識すると多用するのはあまりよろしくなさそうですが、これだけで配列できちゃうの面白くないですか・・・?
ガワが違うが処理が同じなメソッドが多数ある
例えば先ほどの配列の要素数を取得しようと思います。
puts array.length
# 4
僕はjsやっていたので要素数 = lengthなのですが、rubyではsizeでも取得できます。しかも処理内容はlengthと全く一緒なのです。
puts array.size
# 4
他にもこのようなメソッドがたくさんあるので、他の言語開発者も参入しやすい・直感的に記述できるのが「rubyは楽しい言語」と言われている所以でもあるのかなと思ったりしました。
おわりに
他にもclassとかhashとかで思ったことは多々あるのですが、執筆に時間の確保することが難しいのでこのくらいにしておきます(汗)
あとは、Rubyは日本製というのもあってコミュニティが盛んです。僕の住んでる長野県でもRubykaigi 2023があったりするそうです。
もう早割終わっちゃたので参加は断念しますが、こういうところから人脈構成や知見を得やすいのでそういう面でもRubyを学習することはいいことですね!
profile:
Twitter:ヲタクのTwitterです。https://twitter.com/RikuPiku_
Qiita:こっちは真面目です。https://qiita.com/Riku_dazo
Happiness Chainに入会して約2ヶ月間経ったので所感を綴る。
Happiness Chainに入会して約2ヶ月間経ったので所感を綴る。
前回記事はこちら →
一年間独学を貫いてきた僕が今、HappinessChainに入会したわけ - RikuPikuの日記rikupiku.hatenablog.com
こんにちは、RikuPikuです。 前回のブログが意外にも見てくれていて、中にはブログを見てHappiness chainに入会してくれた方もいらっしゃって「ブログの力ってスゲー!」って思いました。他人の人生選択に一枚噛んだって考えるとビビるものがありますが。 本日は23/3/31で入会して大体2ヶ月ほど経ちますので、意識・生活の変化や進行スピードについてちょっとお話しようかと思います。
意識の変化
大きく変化した点は2点です。正直マイナス面の変化はありません。全てプラス面です。
1.同じ学習メンバが可視化できるため闘争心が芽生えた

当スクールではDaily_reportという、学習を行ったら日報を提出することが義務付けられています。そして、任意ではありますが、皆さん学習時間と累計学習時間をカウントしています。
これがいい味出してて、【同じsectionを学んでいるが累計学習時間が僕より低い = その人のほうが効率的に学習を行えている】と認識出来なくもないので......悔しくなります(個人差はあります)
逆に滅茶苦茶勉強してその人を超すと「ふんっ!(鼻息)」となります。良し悪しでいうと悪しに片足突っ込んでる感じは否めませんが、僕はこうやって「同じ目標を持ちかつ土俵が近い人」と勝手に競合することによって、入会してから現在までモチベーションが落ちることはありませんでした。
2.アウトプット癖が付き始めている
各sectionで必ずブログやQiitaでの記事の提出が義務付けられています。結構難しく感じますが、最初は学習をしながらNotinoにメモのようなものを取り、記事に起す手法を取ったためそれほど大変ではありませんでした。
アウトプットをすることで、知識の言語化が必要なため、定着がスムーズになりました。
また、以前学習した内容を忘れてしまった場合、自分で書いた記事を見ることことで確認できますね。同時にその記事を書いていたシーンも連想されるので普通に調べるより定着はしやすいと思います。
僕は技術系の投稿はQiitaで、スクールに関しては当Blogに書くと使い分けることにしています。今のところ調子がいいです。
生活の変化
学習を行う際に一番の敵は「睡魔」でした。

最初の一ヶ月間は、退勤後学習に取り組もうとも睡魔くんが猛威を振るい、実質的学習時間は一時間又は満たない。など苦しめられました。このままではマズイので、退勤後先にお風呂に入ったり、エナジードリンクをがぶ飲みしたりしましたがイマイチ改善しませんでした。 そのまま試行錯誤し、1ヶ月経ったあたりで結論がでました。
改善方法「ちょっと寝る」
眠くなったら20分くらい寝る。これが一番効きました。そのまま爆睡してはいけないので、iphoneとecho dotにアラームをかけ、爆睡しにくい微妙な姿勢で寝ることでその後の1-2時間の学習の質は大幅に上昇しました。おかげといってはなんですが2ヶ月目の学習時間は約20日間で60時間は確保できました。
カリキュラムの進行スピード
一ヶ月目と二ヶ月目でどの程度カリキュラムを進めたかを報告します。 カリキュラムについてはオーナーのゆうだいさんがツイッター上で公開していたような気がしますのでご参照ください。

一ヶ月目:Progate,エンジニアとしての基礎を学ぶ,Web技術の基本を学ぶ,Vim,Linux
所感:progateが意外に時間が取られました。正直Progateはコピペゲーなので以降のsectionは楽しみながらもスイスイと進み、Linuxに着手できるところまで進めました。一ヶ月目はコードも書かなかったため、メンター制度は上手く活用できませんでした。
学習時間は82時間程度です。
二ヶ月目: Linux,Git & GitHub,HTML/CSS,Web開発の基礎を学ぶ,Docker
所感:LinuxはUdemyの動画学習と最強問題集という問題集を全問やるのですが、問題集のほうはUdemyでは紹介されなかったコマンドがほとんどだったため、やってはほぼ全問不正解で二回目で全問正解するみたいな。いきあたりばったりの手法でやっていたため少し時間を裂きすぎたと思います。Git&GitHubではGitHub Flowを回せるようになり、HTML/CSSとWeb開発の基礎を学ぶ は独学期間で学習していたので、一週間程度ですんなりと進めることができ、Dockerに着手するところまでは来ました。また、一週間のうちに1-2日は学習しない期間を設け、燃え尽き症候群や自身への脅迫観念みたいなものを抑制しました。
学習時間は60時間程度です。
おわりに
次回は六月頃に更新しようと思います。(2ヶ月スパンで更新します) Docker section以降はRuby,SQL,REST...とようやくエンジニアぽい内容になってきますが比例して難易度も上がるので、無理せず楽しんでいこうと思います。 今月の学習目標はDocker section修了、rubyに着手です。
ここまで読んでいただきありがとうございました!
一年間独学を貫いてきた僕が今、HappinessChainに入会したわけ
紹介
御閲覧ありがとうございます。Rikuです。 長野の職業訓練校に三ヶ月通い、近くの人材系企業のWeb制作チームとして入社したが会社理念がやばい&何も分からん =パニック発症で試用期間で終了した雑魚雑魚未経験。リベンジのため2022年春頃から改めて独学中でしたが、 2023年1月からHapinnessChainというスクールに入会しました。

1年間の間、スクールに入会しなかった理由
私が約一年もの間スクールに頼らず独学を貫いていたのにはいくつか理由がありました。
1. そもそもいいスクールがなかった
職業訓練校ではHTML/CSSだけを学んだので、色々調べ、転職に必要な技術スタックを把握し、HTML/CSS→JS(Vanilla)→React(Next.js)と改めて学習を進めることにしました。このロードマップに沿ったスクールを探しはしたものの、ほとんどのスクールがHTML/CSS→JS(jQuary)で修了しており、モダン技術を学べるスクールがありませんでした。
2. 独学で技術を取得する自走力がないとエンジニアに成れないと思っていた
エンジニアは技術の転換が素早いので最新の技術をキャッチアップできる自走力が必要不可欠だと知り、達成し自信を持つためにも独学に拘りました。結果は失敗に終わりましたが。
3. 高い
単純に収入が少なく、スクール代が高かったので入会できませんでした。HapinessChainは25000弱/月なので収入-支出が約0にはなりますが、ギリギリまだ入れる金額でした。
何故今スクールに入会しようとしたか
理由は単純です。ほぼ毎日Udemyやら書籍やらでインプットを続け、いざポートフォリオサイトを作ろうとしたとき、何からやればいいのかわからず、何も作れなかったためです。
何故ならば、インプット→課題→アウトプットというルーティンを独学だと極めて生成しにくく、知識が思うように定着していませんでした。
このまま独学を続けても同じことが発生し転職は難しいだろうと悟りました。
一年間独学を続けてこれた自走力は認めようとした(じゃないと努力が水の泡で普通に萎えます)ので、改めてスクールを探したところモダン技術を網羅的に学べるスクールを見つけることが出来たので入会することにしました。
このブログもタスクの一環
この執筆中のブログもスクールのタスクの一環です。各セクションごと学んだことを咀嚼し、自分の言葉で整理することで知識の整理、定着を図っています。地味ですがいままでしてなかったアウトプットですね。
生活費とかお金の心配もありつつ、まだロードマップのスタートラインに立ったばかりですが、未来の自分をより良くするため前向きにプログラミングに向き合っていきたいと思います。